…ÃòI÷«ƒÐ‘⁄CRM÷–µƒë™”√
°°°°±æŒƒ“‘∆ÛòIπп̖≈œ¢œµΩyûȪ˘µA£¨èƒÃΩ”ëCRM±æ…̵ƒÃÿ¸c≥ˆ∞l£¨ΩY∫œîµì˛Õ⁄æÚµƒ‘≠¿Ì°¢SQLSERVER2005µƒBI∆Ω≈_÷–µƒ∑÷Œˆ∑˛Ñ’∫ÕàÛ±Ì∑˛Ñ’£¨þM––“ªÇÄåç¿˝µƒ∑÷Œˆ°£å¶CRMœµΩyµƒ“ª–©ÍPÊI–‘ÓI”ڥʑ⁄µƒÜñÓ}£¨Ã·≥ˆ∆⁄Õ˚µƒΩ‚õQ∑Ω∑®°£
°°°°
°°°°“ª°¢±≥æ∞Àºøº
°°°°£®“ª£©…ÃòI÷«ƒÐ∏≈ ˆ
°°°°…ÃòI÷«ƒÐ£®Business Intelligence£¨∫Ü∑QBI£©µƒ∏≈ƒÓ◊Ó‘Á «Gartner GroupµƒHoward Dresner”⁄1996ƒÍ÷≥ˆÅ̵ƒ°£…ÃòI÷«ƒÐ∏≈ƒÓ∫≠…w¡À≤È‘Éà۱̰¢îµì˛∑÷Œˆ°¢îµì˛Õ⁄æÚ°¢îµì˛Ç‰∑ð∫Õª÷èÕµ»À˘”–“‘éÕ÷˙∆ÛòIõQ≤þûȃøµƒµƒºº–gº∞∆‰ë™”√°£
°°°°…ÃòI÷«ƒÐµƒÍPÊI «èƒåçÎHµƒÝIþ\îµì˛÷–£¨þM––îµì˛ÓAÃé¿Ì£¨»ª∫Û≥È»°£®Extraction£©°¢ÞDìQ£®Transformation£©∫Õ—bðd£®Load£©£¨º¥ETLþ^≥㨿˚”√∏˜∑Nºº–gªÚπ§æþ£¨◊ÓΩKµ√µΩ“ªÇÄ∆ÛòIºâµƒõQ≤þ–≈œ¢°£
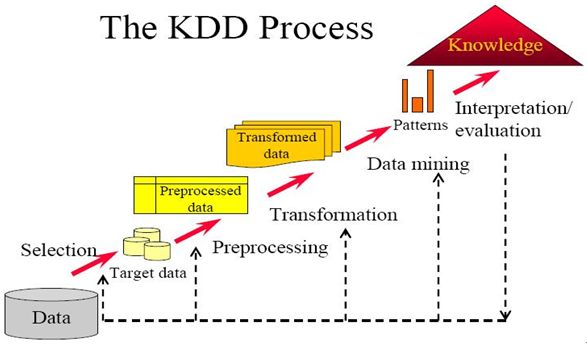
嶔⁄¡„ €––òIµƒõQ≤þ–≈œ¢´@µ√£¨Õ®þ^“ªÇı»ð^–ŒœÛµƒ£¨∏¸ŸNΩ¸Œ“ÇÉ¡„ €∆ÛòI»’≥£ë™”√µƒþ^≥ÃĄ̱̊F£¨º¥îµì˛éϵƒ÷™◊R∞l¨F£®Knowledge Discovery in Database£¨KDD £©°£∂¯‘⁄ø∆—–÷–∑Qµƒ“÷™◊R∞l¨F”£¨‘⁄π§≥ÃÓI”Ú“≤≥£±ª∑QûÈ“îµì˛Õ⁄æÚ”°£
°°°°œ¬àD’π æ¡À÷™◊R∞l¨Fµƒþ^≥ã∫
°°°°
°°°°£®∂˛£©CRM∏≈ ˆ
°°°°‘⁄≤ºŸá∂˜•ŒÈÝñ∑Úµƒª˘µA–‘—–æø°∂Measured marketing°∑÷–√Ë ˆµΩ£¨Ωy”ã÷–∞l¨Fœ˚ŸMÓ~‘⁄«∞30%µƒÓôøÕÿï´Iµƒœ˚ŸMÓ~ «75%,∂¯œ˚ŸMÓ~∫Û30%µƒÓôøÕÿï´Iµƒœ˚ŸMÓ~ÉHÉH «3%°£þ@◊„“‘’f√˜ÓôøÕ‘⁄ŸèŸIƒÐ¡¶…œµƒ≤ªæ˘µ»–‘°£“‘ÓôøÕûÈ÷––ƒµƒ¡„ €Ωõù˙åWµƒ◊⁄÷º «◊åÓôøÕùM“‚£¨å¢∆ÛòIµƒ”–œÞµƒŸY‘¥Õ∂»ÎµΩ◊Ó”–Ér÷µµƒÓôøÕ…Ì…œ£¨ûÈ◊‘º∫µƒ÷“’\ÓôøÕ÷…˝∏¸”–Ér÷µµƒ∑˛Ñ’°£þ@∫Õ¡„ €Æa≥ˆπÐ¿Ì «Æê«˙Õ¨π§µƒ°£
°°°°∂¯å¶”⁄“ªÇÄøÕëÙÍPœµπп̜µΩy£¨∆‰÷˜÷º“≤‘⁄”⁄éÕ÷˙∆ÛòIÕ®þ^ºº–g ÷∂Œ£¨∑÷ŒˆøÕëÙµƒ––ûÈ∫ÕÀ˚ÇɵƒÉr÷µ£¨“‘÷π©∏¸Éûµƒœ˚ŸM∑˛Ñ’º∞øÕëÙÛwÚû°£
°°°°Õ®≥££¨CRMœµΩy∑÷ûÈ∑÷Œˆ–Õ°¢þ\ÝI–Õ°¢Öf◊˜–Õ°£å¶”⁄“ªÇÄ¡„ €∆ÛòIµƒøÕëÙÍPœµπп̜µΩy£¨Õ®≥£ «“‘∏˜∑NΩÈŸ|µƒø®◊˜ûÈðdÛw»•Ωâ∂®ÓôøÕµƒ…Ì∑ð£¨èƒ∂¯ŸNΩ¸ÓôøÕ£¨∑˛Ñ’ÓôøÕ°£À˘“‘嶔⁄“ªÇÄ¡„ €∆ÛòIµƒøÕëÙÍPœµπп̱ÿ»ªï˛…ʺ∞µΩø®πп̣¨Õ¨ïr∫≠…wøÕëÙ∑÷Œˆ∫ÕúœÕ®µ»°£
°°°°Õ®≥£å¶”⁄îµì˛∑÷Œˆµƒ–Ë«Û£¨ø…“‘∑÷ûÈ£∫
°°°°1°¢øÕëÙ∏≈õr∑÷Œˆ£∫øÕëÙµƒå”¥Œ°¢ÔLÎU°¢ê€∫√°¢¡ïëTµ»£ª
°°°°2°¢øÕëÙ÷“’\∂»∑÷Œˆ£∫ª˘”⁄ÓêÑeπп̣¨øº≤ÈøÕëÙÓêÑeÞD“∆∫Õ◊Éπù£¨º∞øº≤ÈΩõù˙÷“’\∫ÕÍPœµ÷“’\£ª
°°°°3°¢øÕëÙ¿˚ùô∑÷Œˆ£∫≤ªÕ¨øÕëÙÀ˘œ˚ŸMµƒÆa∆∑µƒþÖæâ¿˚ùô°¢øÇ¿˚ùôÓ~°¢ÉÙ¿˚ùôµ»£ª
°°°°4°¢øÕëÙ–‘ƒÐ∑÷Œˆ£∫≤ªÕ¨øÕëÙÀ˘œ˚ŸMµƒÆa∆∑∞¥∑NÓê°¢«˛µ¿°¢‰N €µÿ¸cµ»÷∏òÀÑù∑÷µƒ‰N €Ó~£ª
°°°°5°¢øÕëÙŒ¥ÅÌ∑÷Œˆ£∫姒“øÕëÙø°¢ÓêÑeµ»«ÈõrµƒŒ¥ÅÌ∞l’π⁄ÖÑ𣨓‘Ýé»°øÕëÙ£ª
°°°°6°¢øÕëÙÆa∆∑∑÷Œˆ£∫÷˜“™·ò嶅Ã∆∑µƒÍP¬ì∑÷Œˆ£¨º∞…ʺ∞µƒπ©ë™ÊúÉûªØ£ª
°°°°7°¢øÕëÙ¥Ÿ‰N∑÷Œˆ£∫∞¸¿®ý]àÛªÚΩµÉrµ»¥Ÿ‰NªÓÑ”µƒπп̰£
°°°°∂˛°¢ë™”√åç¿˝
°°°°£®“ª£©ÓôøÕÓêÑeπпÌ
°°°°±æåç¿˝µƒƒøµƒ «ÑìΩ®“ªÇÄ∫ÜÜŒµƒÓôøÕ∑÷Ó꣨‘⁄ÓôøÕ∑÷Ó굃ª˘µA…œ£¨þM––œý뙵ƒ…Ã∆∑∆∑ÓêŸèŸIµƒ∑÷Œˆ°£
ª˘”⁄ÓôøÕÓêÑeπп̵ƒ¿Ì’죨≤ªø…ƒÐ‘⁄∑÷Œˆïr÷±Ω”·òå¶ÜŒ“ªÓôøÕþM––∑÷Œˆ£¨øœ∂® «å¶Õ¨“ªÓêÑeµƒÓôøÕ£¨þM––œý뙵ƒœ˚ŸM––ûÈ¡ïëT∑÷Œˆµ»°£þ@æÕ»ÁÕ¨…Ã∆∑“™þM––∆∑Óêπп̵ƒµ¿¿Ì“ªò”°£Æî÷ª”–þM––ÓôøÕµƒÓêÑeπпÌïr£¨≤≈ƒÐ»•øº≤ÈÓêÑe»ÀîµÞD“∆¡ø£¨þ@ «ï˛ÜTπпÌ≥…–ßµƒ“ªÇÄ÷ÿ“™÷∏òÀ°£“≤÷ª”–þ@ò”£¨≤≈ƒÐå¶◊Éπù¬ µ»÷∏òÀþM––
øº≤È°£
°°°°Œ“ÇÉÕ®≥£þM––µƒÓôøÕ∑÷Ó꣨∂º «¿˚”√øÕÜŒ¡øªÚŸèŒÔÓl¥ŒÑù“ª∏˘æÄ£¨ÅÌΩÁ∂®∑÷Ó굃œÛœÞ°£∂¯’Ê’˝µƒÓôøÕæ€Ó꣨ծ≥£øºë]¡ÀøÕÜŒ°¢Ól¥ŒªÚ’þ ’»Îµ»µ»æC∫œ“ÚÀÿ∂¯åç¨F°£Õ®þ^∫ÜÜŒµƒÑùæÄ Ω∑÷Ó꣨üo∑®þ_µΩ“»À“‘»∫∑÷”µƒ–ßπ˚°£
°°°°£®∂˛£©æ€Óê∑÷Œˆ
°°°° æ€ÓêÀ„∑®”–ƒÐ¡¶∞l¨F”√ÅÌå¶îµì˛þM––∑÷ΩMµƒÎ[–‘◊É¡ø£¨“Ú¥À嶔⁄¡„ €––òIÅÌ’f£¨æ€ÓêÀ„∑® «“ª∑N∑«≥£¡˜––µƒîµì˛Õ⁄æÚºº–g°£
°°°°å¶”⁄æ€ÓêÀ„∑®ÅÌ’f£¨≥£”√µƒ”–É…∑N£∫K-∆Ωæ˘∫ÕK-÷––ƒ¸c°£
°°°°‘⁄SQLSERVER2005 BI Development Studio÷–µƒæ€ÓêÀ„∑®“≤”–É…∑N£¨K-meansÀ„∑®∫ÕEMÀ„∑®£¨þ@É…∑N∂º «åŸ”⁄K-∆Ωæ˘À„∑®µƒ°£
°°°°K-meansÀ„∑® «“‘æýÎx÷µµƒ∆Ωæ˘÷µå¶æ€Óê≥…ÜTþM––∑÷≈‰£¨√øÇÄå¶œÛ «‘⁄“ªÇÄæ€Óê÷–£¨æ€Óê∫Õæ€Óê÷ÆÈgª•≤ª÷ÿØB, Õ®≥£±ª’JûÈ «”≤æ€Óê°£∂¯EMÀ„∑®‘á”√∏≈¬ þM––∂»¡ø,“ªÇĸcø…ƒÐ埔⁄∂ýÇÄæ€Ó꣨√øÇÄæ€Óê”–≤ªÕ¨µƒ∏≈¬ £¨æ€Óê÷ÆÈg «ø…“‘÷ÿØBµƒ£¨Õ®≥£±ª∑QûÈÐõæ€Ó갣嶔⁄Îx…¢åŸ–‘µƒæ€Óê «þm∫œ π”√EMÀ„∑®µƒ°£
°°°°Microsoftµƒæ€ÓêÀ„∑®”–“ªÇÄø… ’øs‘≠¿Ì£¨å¶”⁄“ªÇÄø… ’øsµƒøںУ¨ÆîþM––÷ÿèÕ”ñæöïr£¨å¶”⁄≤ªï˛‘⁄æ€Óê÷ÆÈg“∆Ñ”µƒîµì˛£¨∂º∞—À˚ÇÉâ∫øs£¨≤ªº”ðdµΩÉ»¥Ê£¨þ@ò”æÕâ∫øs¡ÀÉ»¥Êø’Èg°£
°°°°SLQ Server Analysis Services”–É…ÇÄ÷˜“™µƒîµì˛Õ⁄æÚ嶜ۣ∫Õ⁄æÚΩYòã∫ÕÕ⁄æÚƒ£–Õ°£Õ⁄æÚΩYòã”√ÅÌ∂®¡xÕ⁄æÚÜñÓ}µƒå¶œÛ£¨∂¯Õ⁄æÚƒ£–Õ «Õ⁄æÚÀ„∑®å¶Õ⁄æÚΩYò㵃æþÛwë™”√°£
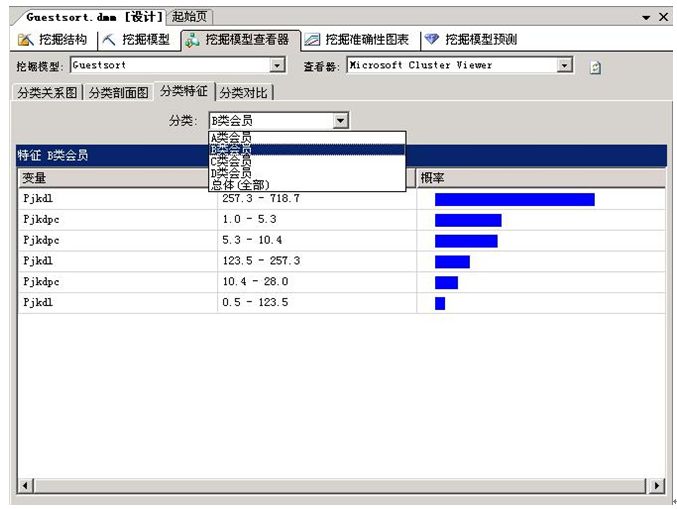
°°°° ±æπù÷–œ¬√ʵƒ¿˝◊”£¨ «‘⁄SQL Server Analysis Services∑˛Ñ’µƒ∆Ω≈_…œ£¨–¬Ω®µƒ“ªÇÄanalysis servicesÌóƒø, ë™”√ø… ’øsµƒk-meansæ€ÓêÀ„∑®ƒ£–Õ£¨“‘ƒ≥¥Û–Õ≥¨ –Ω¸∞΃͵ƒï˛ÜTœ˚ŸMîµì˛ª˘µA£¨÷ªÕ®þ^øÕÜŒ¡ø∫ÕÓl¥ŒÉ…ÇÄæS∂»£¨å¶ï˛ÜTþM––∫ÜÜŒ∑÷Óê°£øÇπ≤∑÷≥…¡À4Óêï˛ÜT°£‘⁄∫Û√ÊàÛ±Ìë™”√ïr£¨å¢∫ÜÜŒµƒ“‘A°¢B°¢C°¢DÅÌòÀ◊R°£ ◊œ»»Áœ¬àDÔ@ æ£∫
°°°°
°°°°–Ë÷µµ√◊¢“‚µƒ «£¨‘⁄þM––îµì˛ÓAÃé¿Ìµƒïr∫Ú£¨Ìöœ»þM––îµì˛µƒ«Âœ¥°£å¢“ª–©¿¨ª¯îµì˛«Â≥˝£¨å¢–Ë“™µƒîµì˛þM––º”π§°£
°°°°
°°°°å¶”⁄SLQ Server Analysis ServicesµƒÕ⁄æÚΩYπ˚µƒ∞l≤º£¨ø…“‘÷±Ω”Õ®þ^DMX’Z—‘þM––≤È‘É£¨ªÚ’þÕ®þ^SQLSERVER2005 BI Development StudioÅÌÑìΩ®à۱̃£–ÕÅÌ’π æ°£à۱̃£–Õµƒ π”√‘⁄œ¬“ªπù÷–î¢ ˆ°£þ@¿Ôœ»’f√˜œ¬DMX’Z—‘µƒ π”√°£
°°°°îµì˛Õ⁄æÚîU’π≤º˛ (DMX) «“ª∑N’Z—‘£¨‘⁄ Microsoft SQL Server 2005 Analysis Services (SSAS) ÷–ø…“‘ π”√‘ì’Z—‘ÑìΩ®∫ÕÃé¿Ìîµì˛Õ⁄æÚƒ£–Õ°£ø…“‘ π”√ DMX ÑìΩ®–¬îµì˛Õ⁄æÚƒ£–ÕµƒΩYòã°¢ûÈþ@–©ƒ£–Õ∂®–Õ≤¢å¶∆‰þM––ûg”[°¢πпÌ∫ÕÓAúy°£DMX ”…îµì˛∂®¡x’Z—‘ (DDL) ’Z扰¢îµì˛≤Ÿ◊˜’Z—‘ (DML) ’Z打‘º∞∫Øîµ∫Õþ\À„∑˚òã≥…°£∆©»Á‘⁄…œ¿˝÷–»Á∫Œ’“µΩƒƒ–© «“BÓêï˛ÜT”µƒ£∫
°°°°SELECT t.cardcode From [Guestsort] PREDICTION JOIN OPENQUERY([Hd31],
°°°°'SELECT [cardcode],[pjkdl],[pjkdpc] FROM [dbo].[guestsort] ') AS t
°°°°ON [Guestsort].[Pjkdl] = t.[pjkdl] AND [Guestsort].[Pjkdpc] = t.[pjkdpc]
°°°°where Cluster() = 'BÓêï˛ÜT'
°°°°Æ»Áπ˚≤ªœÎþ@≤ø∑÷ï˛ÜTµƒ∑÷ÓêΩ–“BÓêï˛ÜT”£¨∂¯∏ƒ∑QûÈ“∞◊„yï˛ÜT”ªÚ∆‰À˚∑Q∫Ù£¨ƒ«√¥“≤ «ø…“‘Õ®þ^DMX’Z—‘ÅÌ–Þ∏ƒÕ⁄æÚƒ£–ÕµƒÉ»»ðµ√µΩ°£
°°°°£®»˝£©àÛ±Ì∞l≤º
°°°°…œ“ªπù÷µΩ¡À∞l≤ºîµì˛ø…“‘Õ®þ^Reporting ServicesÅÌ’π æ°£Reporting Services÷π©¡À“ªÇÄÑìΩ®∂®÷∆à۱̵ƒôC÷∆£¨þ@ÇÄàÛ±ÌÕ®≥£∞¸∫¨Œƒ±æ∫ÕàD–Œ£¨ø…“‘Õ®þ^HTML°¢Email°¢¥Ú”°–Œ Ω∫ÕMicrosoft OfficeŒƒôn∞l≤º°£ª˘”⁄WebµƒàÛ±Ìø…“‘ «Ωªª• Ωµƒ£¨Õ®þ^‘ˆº”àÛ±ÌÖ¢îµåç¨FΩªª•ƒøµƒ°£
°°°°±æπù÷–œ¬√ʵƒ¿˝◊”£¨ «ª˘”⁄ÓôøÕÓêÑeπп̵ƒª˘µA…œ£¨å¶A°¢B°¢C°¢D≤ªÕ¨ÓêÑeµƒÓôøÕÀ˘ÍP–ƒ°¢ŸèŸIµƒ…Ã∆∑∆∑ÓêþM––µƒΩy”ã∑÷Œˆ°£»Áπ˚å¢þ@ÇÄþ^≥ÃþM“ª≤Ωºö∑÷µƒ‘í£¨ƒ«æÕ «·ò嶅Ã∆∑ºâÑeµƒÍP¬ì“éÑtµƒë™”√£¨þ@ÇÄ‘⁄þ@¿Ô≤ªþM––”ë’ì°£þ@¿Ô÷ª «Õ®þ^…Ã∆∑∆∑Óê∫Õï˛ÜTÓêÑeµƒæÿÍá Ω’π 棨ð^∫ÜÜŒµÿÛw¨FReporting Servicesµƒπ¶ƒÐ°£
°°°°Õ¨ò”‘⁄SQLSERVER2005 BI Development Studioø…“‘»•ÑìΩ®“ªÇÄReporting ServicesÌóƒø°£îµì˛‘¥ø…“‘ «ÍPœµîµì˛éÏ£¨“≤ø…“‘ «Analysis Servicesµ»°£æþÛwµƒþ^≥Ã≤ª√Ë ˆ¡À£¨èƒîµì˛‘¥÷–◊ÓΩKµƒà۱̌ƒ±æªÚàD–Œµ»£¨þM––…˙≥…°¢≤ø £¨◊ÓΩKø…“‘Õ®þ^webµƒ∑Ω ΩþM––ûg”[°£ œ¬àD æ“‚¡À“ªÇÄ∫ÜÜŒîµì˛µƒ∞l≤º£∫
°°°°Õ®þ^web’π 浃æÿÍá∏Ò Ω£¨––¥˙±Ì…Ã∆∑ÓêÑe£¨¡–¥˙±Ìï˛ÜTÓêÑe£¨“‘Ô@ æ≤ªÕ¨ÓêÑeï˛ÜTå¶≤ªÕ¨∆∑Óê…Ã∆∑µƒŸèŸI«Èõr°£
°°°°Õ¨ïr…œàD“≤ æ“‚¡À“ªÇÄΩªª•µƒþ^≥ã¨ø…“‘Õ®þ^”√ëÙ÷∏∂®µƒ…Ã∆∑ÓêÑeÅÌ≤Èø¥∏–≈d»§µƒîµì˛°£±»»Á≤Èø¥÷–Óê3000µƒ…Ã∆∑±ªA°¢B°¢C°¢DÀƒÓêï˛ÜTµƒŸèŸIÓl¥Œº∞∆∑ÓêΩÓ~«Èõr°£Æ“≤ø…“‘‘ˆº”∆‰À˚µƒ≤È‘Éólº˛°£
°°°°å¶∏–≈d»§µƒÓêÑe÷ß≥÷ò‰–ŒΩYò㵃◊‘”…’πÈ_£¨œ¬„@µΩ–°Ó꣨◊”Óê°£»Á…œàDµƒ30000–°Óê∫Õ30001–°ÓêæÕ’πÈ_√˜ºöµΩ∏˜◊‘µƒ◊”Óê÷–°£
°°°°å¶”⁄à۱̵ƒΩYπ˚ø…“‘åß≥ˆµΩXML,HTML,PDF,EXCELµ»µ»Œƒº˛÷–°£
°°°°àÛ±Ì∆Ω≈_÷ß≥÷Õ¨ïr“≤÷ß≥÷å¶∏˜∑NΩ«…´µƒôýœÞπп̺∞»’≥£µƒ”ÜÈÜ∑˛Ñ’µ»°£
°°°°»˝°¢ë™”√«∞æ∞
°°°°èƒƒø«∞µƒåçÎHë™”√ÅÌø¥£¨æ€Óê∑÷Œˆ◊˜ûÈîµì˛Õ⁄æÚµƒ“ª∑NÀ„∑®ƒ£–Õ£¨þÄ”–∫Ð∂ý–Ë“™÷µµ√»•’{’˚µƒµÿ∑Ω£¨∆©»Á£∫»Á∫Œîµì˛ÓAÃé¿Ì£¨»Á∫ŒÃÞ≥˝¥Û–Õ¥Ÿ‰Nµ»£¨‘Ï≥…µƒîµì˛ÆêÑ”……
°°°°∂¯å¶”⁄CRM±æ…̵ƒ7¥Û∑÷Œˆ–Ë«Û£¨“≤–Ë“™∏¸∂ýµÿÕ⁄æÚƒ£–ÕþM––åç€`°£±»»Áøº≤ÈÓôøÕÓêÑeÞD“∆ïr£¨ø…“‘ π”√–Ú¡–æ€ÓêÀ„∑®°£Æa∆∑∑÷Œˆïr£¨ø…“‘ π”√ÍP¬ì“éÑt°£∂¯å¶”⁄Õ¨“ª∑NòIÑ’àˆæ∞£¨ë™”√≤ªÕ¨À„∑®“≤墵√µΩ≤ªÕ¨µƒΩYπ˚°£“Ú¥Àø…“‘Õ®þ^Õ⁄æÚú ¥_–‘àD±Ì£¨å¶Õ⁄æÚƒ£–Õ±æ…ÌþM––≤ªîýµƒ–Þ’˝°£
°°°°ø…“‘ÓA∆⁄‘⁄Œ¥Å̵ƒë™”√þ^≥Ã÷–£¨ΩY∫œ…ÃòI÷«ƒÐ¿Ì’쵃뙔√£¨Õ®þ^ÓôøÕÍPœµπп̣¨å¢ûÈÓôøÕéßÅÌ∏¸√¿∫√µƒœ˚ŸMÛwÚû£¨Ωo¡„ €…ÃéßÅÌ∏¸∂ýµƒ‰N €Ã·…˝°£
